The 7th Keep Austin Agile conference hosted 600 Agile practitioners from over 200 companies for a full day of education and networking. In this post, we summarize the key sessions and takeaways from this year’s Keep Austin Agile.
Our Growing Space Traffic Problem: Another Inconvenient Truth
The keynote by Dr. Moriba Jah on the growing space traffic and its associated problems was quite an eye-opener. He explains that of the 500,000 human-made objects in space, we currently track 26,000. These are objects that can cause loss, disruption, or degradation of critical services that we depend on.
With private companies finding success and profits in space exploration, a new industry is emerging, with approximately 15,000 satellites being planned for launch in the next five years. While we do launch satellites in specific “space highways”, we do not have traffic rules. In this session, Dr. Jah talks about how software, sensors, algorithms, and analytics can keep pace with reality and deliver on space safety and sustainability. In space, the critical question is whether an object is debris that can wreak havoc. However, there are a few challenges in the way this works. Though many countries have their launches, there is no systematic data sharing between space agencies. Absent is the knowledge of what “normal” means in space terms. There is a lack of transparency in the way space operations are conducted.
Dr. Jah introduces the concept of Space Situational Awareness (SSA) and Space Traffic Management (STM). Space is a hazardous environment and needs to be understood and managed. Paths of objects are only estimates, and the results of them colliding are catastrophic.
He further emphasizes the need for data about these objects and understanding its significance. He cautions against inferences and instead pushes the audience to base their decisions on data and further corroborate these data points from multiple sources. Partial knowledge is dangerous and can lead to erroneous decisions.
Dr. Jah talks about Ontologies and how it can help us better understand this environment. He further listed unsolved challenges.

Cognitive Automation: Applying AI/ML to tasks within the SDLC by Geoff Meyer, Test Architect, Dell EMC
The culture of automation has seen unprecedented acceptance within the software development community. Companies that already have the Agile way of software development are exploring the realm of AI-driven software testing.
Analytics, natural language processing, and machine learning are AI-inspired automation paths that are now powering the next generation of testing products and services. Meyer refers to this as Cognitive Automation – essentially tasks that up until now only a human could perform.
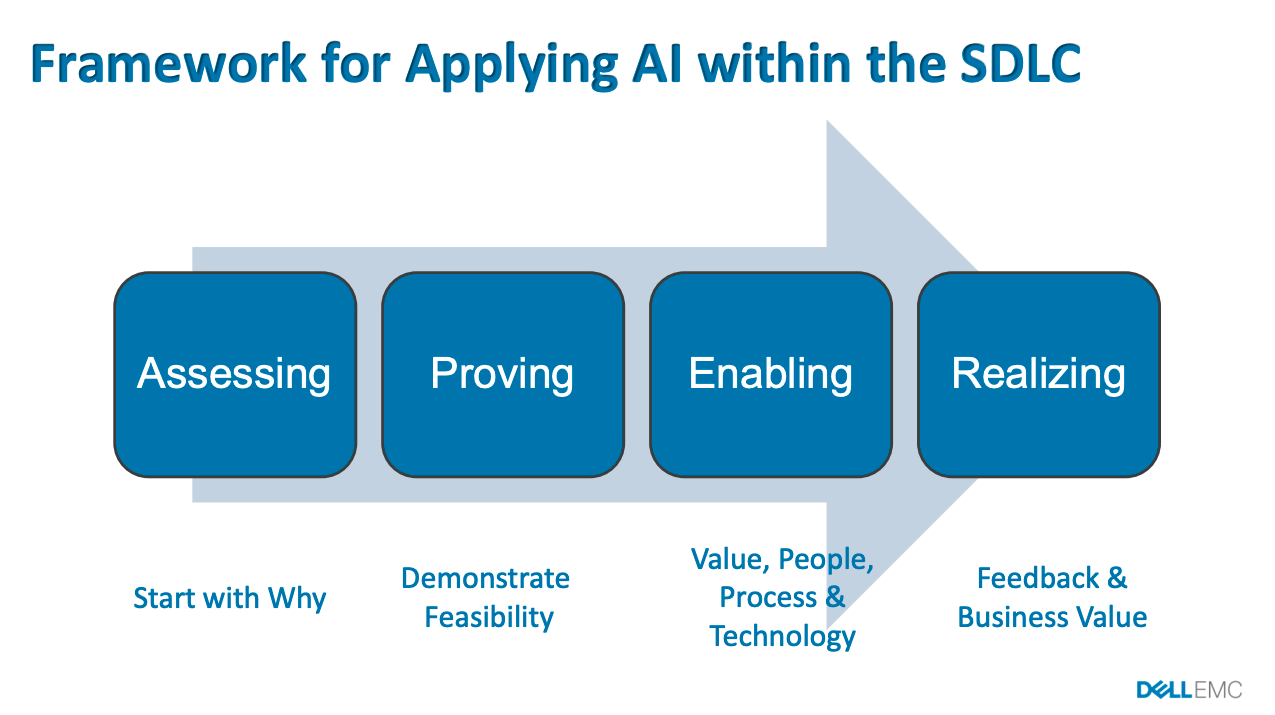
While the concept of AI-driven testing is fascinating, Meyer cautions against overhype and inherent complexities as compared with current proven automation techniques. Meyer’s session provides organizations with a framework to use when considering using AI-based technologies in their SDLC. To drive home the abilities of AI-based testing, Meyers states that there are 465 trillion test configurations for Dell EMC servers. He further talks about the use of smart assistants to test high-value configurations.
Meyers delves deeper into his framework that starts with the thinking behind the identification and selection of high-value configurations from these 465 trillion combinations. He then outlines the test planning model that uses historical test data and defects as predictors to expose patterns.
The objective of this model is to automate deep-thinking tasks and codify subject matter expertise. AI-assisted test bots substantially increase coverage for UI testing at less cost of creation and maintenance.
Meyers then discusses the framework for applying AI within the SDLC.
Scaling an Organization from First Principles by Tristan Slominski
Tristan Slominski’s presentation focuses on the concept of scale. In the first part of his talk, Slominski shows how small components come together to form larger ones with defined interfaces. These more significant components then interact in complex ways with even more defined interfaces. He states that at a different scale, things seem different and yet have enormous consequences and how we should make sense of this complexity.
One way to make sense of this complexity is by using the Cynefin framework.
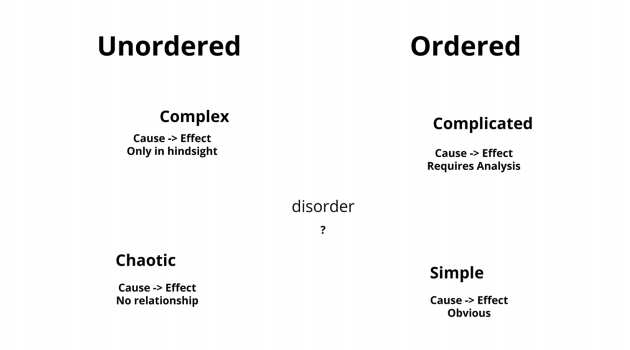
Slominski then proceeds to explain that the laws of physics do not change on the time scale we care about, and the constraints we operate within remain fixed. He describes the Universal Scalability Law that states that the time it takes for data to become coherent and the added coordination between data points kills throughput significantly.
Slominski applies this law to team scalability. As and when we add more resources, we add more feedback loops through more coordination between these resources. More resources need more time to communicate and exchange data with each other for them to do their jobs. As we add more teams of resources, conventional wisdom states that more coordination is required, which has a decimating effect on throughput. He then shows that by eliminating these feedback loops and coordination we can substantially improve throughput. We now change the scale from the number of resources to teams of resources. Consequently, our perception of the scale of throughput should also change.
Essentially, replacing the feedback loops with an API means that at the team scale, there is just one feedback loop, which is that of the API. In the absence of an API, we as people end up coordinating with other people. This coordination slowly builds up the complexity we are trying so hard to contain.
Enter Service Level Objectives (SLOs). Service Level Objectives try to measure the performance objectives needed of an API. The SLO restricts the inter-team coordination required, thus allowing an organization to shift towards the team scale. APIs and SLOs form a container that abstracts the complexity so that at the organizational scale, we can accomplish more – and generate new complex sources of worth.
“He’s Going Vertical. So Am I” – Making and Keeping Your User Stories Vertical by Mark Ulferts and Melissa Ugiansky
In this session, Ulferts and Ugiansky detail the benefits of working with vertical stories.
80% of customer value resides in just 20% of the product features. Horizontal stories have shortcomings that prolong the development cycle. Even worse, according to the Standish Group Research, 65% of the features have little to no value.
The presenters start by showing that horizontal stories prolong development cycles, have longer feedback loops to demonstrate value. They often lead to waterfall methods of development, which are wasteful and anti-Agile.
Ulferts and Ugiansky present the vertical stories hypothesis, which is easier to prioritize, can show demonstrable value within shorter periods, and deliver real customer value.
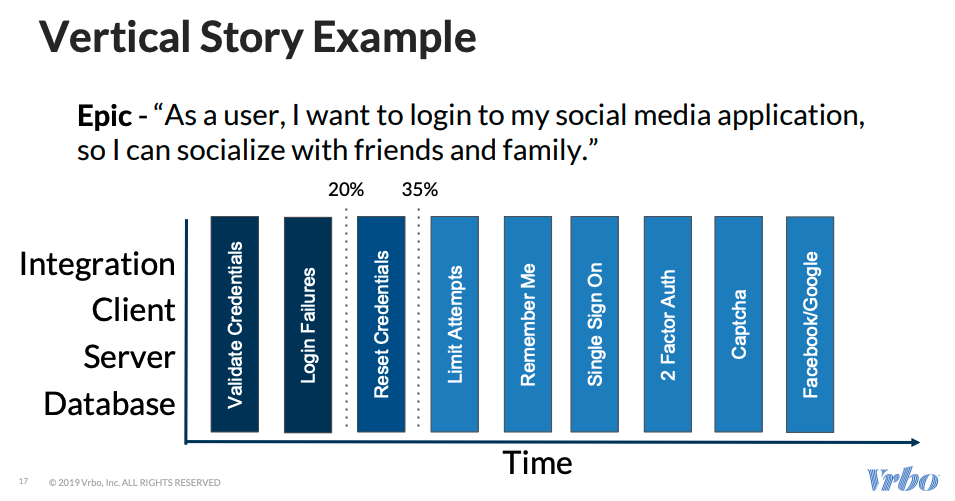
The process of vertical stories begins with defining personas. These are then tagged with the features flags that are prioritized. Features flags are critical to vertical stories. They help release code that is still in development and even test them while in production. It also enables a faster user feedback loop with incremental rollouts. Vertical stories also accelerate continuous deployment with quick rollbacks and recovery.
Vertical stories use specific story splitting techniques as shown below,
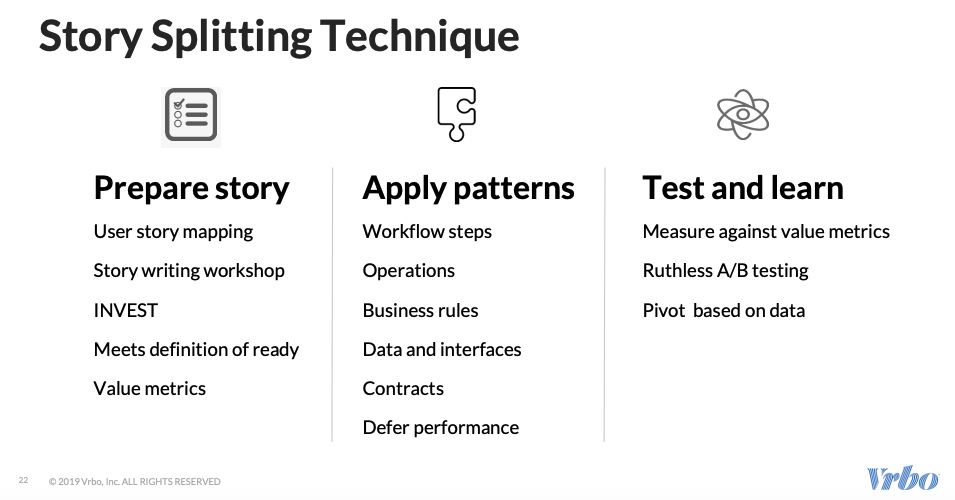
They then show how to map product features with what must be the workflow. Workflows are divided into logical steps. For example, the top 20% of must-have features can prioritize some steps over others. This keeps a tight workflow that focuses specifically on the features that users use.
Vertical stories have a laser focus on the user and their satisfaction. Every outcome is tracked and measured against the users’ opinion of the feature and its outcomes. All features are then prioritized based on A/B testing. This helps the product pivot based on real-world performance data.
Agile Development and the Era of Quality Intelligence by Dan Belcher
Quality Assurance in software development often carries the perception of a staid function. It is often undervalued by software executives, entrepreneurs, and venture capitalists alike. However, with emerging practices such as DevOps and Continuous Delivery, QA’s role is changing. In this session, Dan Belcher talks about how former manual testing practices will evolve and ultimately morph into a broader test-automation framework that he refers to as “Quality Intelligence”.
Effective test automation is integral to DevOps. Belcher states that at mabl they have upto 100 commits every week. In many cases, testing can become a bottleneck in the delivery process. Development cycles are now shorter and there simply isn’t enough time to test. Cloud makes testing faster while intelligence makes it easier. We now know how to make automation work well. With AI and automation intelligence Belcher lays the foundation for Quality Intelligence. Automated tests are easier to create and maintain. Capturing intent and no scripting reduces automated test creation time by 85%. Auto-healing tests have sophisticated heuristics that adapt or “heal” when the application changes.
Data from DOM snapshots, HTTP archives, and Chrome traces when combined with Cloud execution results in insight. Product owners often combine this insight with feedback from the users to base their decisions on product features. Performance analysis, visual change detection, and model-driven change detection reduce regression cycles by 50%.
Belcher states that analytics will become increasingly critical at scale and tools that help test are becoming sophisticated. In the end, he talks about what the new job description for testers would be and what tools they would find useful.
All the Sugar and Twice the Caffeine Applying Design Thinking Within an Agile Transformation by Mary Grace Francisco and Andy Switzky
In this session, Mary Grace Francisco and Andy Switzky explore how you can apply Design Thinking methods in your everyday work during a Lean UX and Agile Transformation.
Francisco and Switzky talk about LUMA, a company with their flavor of Design Thinking that is a combination of Human Centric Design (HCD), Lean and Agile. HCD focuses on empathizing with the user to understand their needs and how you can meet their needs. The LUMA-based framework focuses on generating a lot of ideas and experimenting with prototypes.
Applying Lean principles to product design helps build the right things. This part of the model focuses on identifying the assumptions, defining experiments to test these assumptions and then iterating. The Agile part of the model focuses on defining features that aid in meeting users’ needs, delivering them via short sprints and then iterating. This interactive session then invited the audience to start listing their questions about Lean UX. These questions were then grouped by similarities. Essentially, this is affinity clustering where you identify themes around these questions.
Francisco cautioned the group to not label the clusters too early in the cycle since they may change later on and prevent further thinking on it later. Clustering is also a group activity where everyone can discuss and agree on the grouping for items. The group then votes on the questions that they feel are the most important or if they want to explore further.
The next step is a guided ideation and brainstorming session where we try and answer questions in the previous sessions. Here people can be grouped into teams and the whole session can be gamified.

More information on sessions from Keep Austin Agile 2019 can be found here.
If you liked this post, here are a few more that may interest you,